I was thinking about the Mandelbrot set the other day - I cannot remember exactly why but this is the sort of thing that happens to someone who is a mathematician by nature. While I was growing up computers were beginning to become commonplace in people's homes and the Mandelbrot set, being a pretty way of showing off the capability of these new toys, was in fashion and I knew what it looked like before I had any idea what it meant.
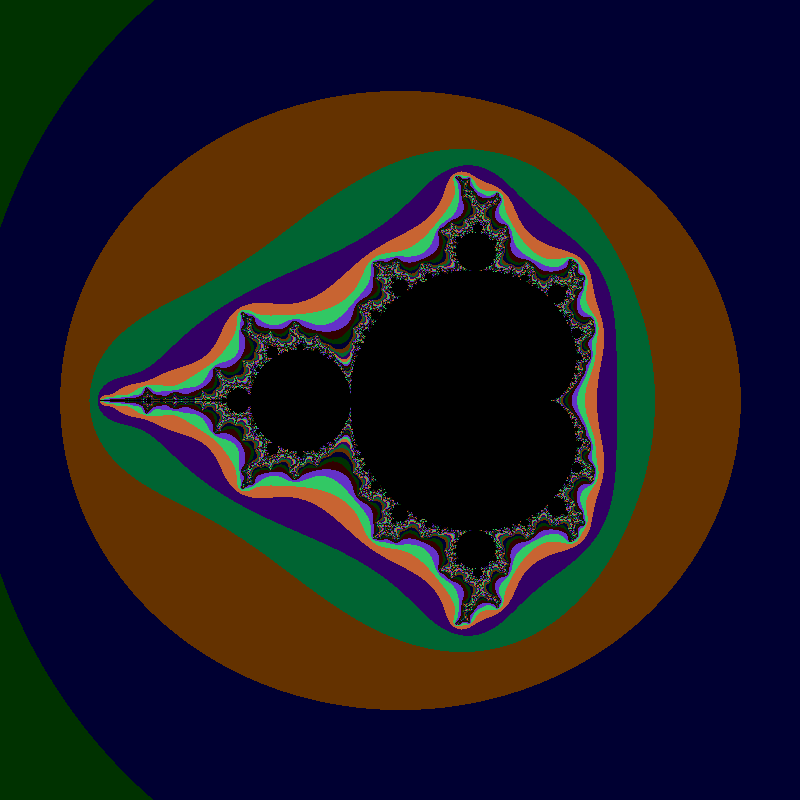
Most people think of the Mandelbrot set as an intricate pattern made up of lots of coloured shapes somewhere between circles and triangles (see left). However, as I discovered, the set is in fact the black bit in the middle and all the coloured bits are precisely what the set is not. In fact, the colour of the points shows how quickly they can be discarded.
However, as I discovered, the set is in fact the black bit in the middle and all the coloured bits are precisely what the set is not. In fact, the colour of the points shows how quickly they can be discarded.
As well as being a mathematician I also work a lot with databases and my recent thoughts about the Mandelbrot set centered around the possibility of creating it in a database, specifically a MySQL database.
There are numerous explanations of the Mandelbrot set out on the Internet but it would make sense to have a brief introduction here. If you cast your mind back to mathematics at school you may recall that there are methods of solving equations like , where is a constant. For some values of it would be possible to factorise this equation to find integer solutions while for other values a formula can be used. Alternatively you could note that the equation can be re-written as and then use a method of iteration by guessing a solution and, by repeatedly evaluating the right-hand-side of the equation get better guesses. For example, in the case of we might guess the solution to be zero and then, by following this iteration, get the following sequence:
| Guessed | = next guess |
|---|
| 0 | -0.5 |
| -0.5 | -0.25 |
| -0.25 | -0.4375 |
| -0.4375 | -0.3086 |
| -0.3086 | -0.4048 |
| (etc) | (etc) |
| -0.3661 | -0.3660 |
| -0.3660 | -0.3660 |
and -0.3660 turns out to be the solution, to four decimal places. A computer is very good at this sort of thing and, when the equation is more complicated, this method is extremely useful for finding an estimate of the solution. It is quite satisfying when this works out but, unfortunately, this isn't always the case. Take , which has the nice, easy solutions of 4 and -3.
| Guessed | = next guess |
|---|
| 0 | -12 |
| -12 | 132 |
| 132 | 17412 |
| (etc) | (etc) |
| lots | even more |
| even more | giving up yet? |
The Mandelbrot set is essentially the set of all numbers for which the iterative method , starting with , remains bounded. However, it is a bit more complex than that (did you see what I did there? Eh? Oh, never mind) because this description simply results in the set of numbers from -2 to 0.5 and certainly not the intricate multi-coloured pictures that everyone remembers. We are actually concerned with complex numbers, which may be represented in two dimensions. For those unfamiliar with complex numbers, they can be though of as Cartesian coordinates in a plane and the only mathematics we need to do with them for the purpose of this is:
- adding two complex numbers together, which is
- squaring a complex number, which is
With these two operations we can do everything we need with the equation . However, instead of x and y I will use Real (or Re) and Imaginary (Im).
So what has this got to do with databases? The usual way in which programs were written to generate a Mandelbrot set was to go through each point on the plane in turn, taking that value as c, and iterate over the function until it could be decided whether or not the value would stay within a boundary. After doing this the point is drawn as black if remained within the boundary or a colour determined by how quickly it grew. The algorithm for this looks like:
Start of main loop
Choose next point, c
Set z=0
Start of iteration loop
Calculate z_new = z^2+c
If z_new is too large
c is not in the set
Else if we have tried enough iterations
c is in the set
Else
Go back to the start of the iteration loop with z=z_new
End of iteration loop
If there are more points to try
Go back to the start of the main loop
This algorithm is very simple and has probably been written for most conventional programming languages. I did check to see if it had been written in SQL and indeed it had in a few of places, for T-SQL, Postgres and MySQL but in all these cases the algorithm above had been replicated in each flavour of SQL to 'plot' the graph in ASCII art. This is a nice trick but completely ignores the fact that working with a large set of data, performing the same operation on every point, is exactly what SQL is good for. If the points are stored in a database then one step of the iteration can be performed on every point at the same time with one query rather than laboriously stepping through each one at a time. The algorithm then becomes:
Populate the database with all the values of c
Set z=0 for every point
Loop
Update all rows in the database setting z to be z^2+c
Mark all rows where z is too large as not in the set
Repeat the loop until bored
For each point I needed the number
and the current value of
at a particular point in the iteration. Both of these are complex numbers and so have a real and imaginary part. I also need a flag to say whether or not the point is known not to be in the set - I call this 'active' and set to 1 if the point is still to be iterated. Finally, I need a count for the number of iterations that have been performed on the point, so that the picture can be coloured correctly. The table therefore looks like:
| Real part of c | c_re DOUBLE |
| Imaginary part of c | c_im DOUBLE |
| Real part of z | z_re DOUBLE DEFAULT 0 |
| Imaginary part of z | z_im DOUBLE DEFAULT 0 |
| Iterative steps count | steps INT DEFAULT 0 |
| In set (1=yes) | active CHAR DEFAULT 1 |
With the table set up like this my first attempt, which contains an error (can you spot it?), was to perform the iteration with:
UPDATE points SET
z_re=POWER(z_re,2)-POWER(z_im,2)+c_re,
z_im=2*z_re*z_im+c_im,
steps=steps+1
WHERE active=1;
This would perform one iteration on every point in the plane that had not already been determined as not in the set. The next step is to determine which points can be discounted.
UPDATE points SET active=0
WHERE POWER(z_re,2)+POWER(z_im,2)>4;
 The value of 4 as the bound comes from noting that the entire Mandelbrot set falls within a circle of radius 2 centred at the origin. These two queries, repeated multiple times, should be all that is required to generate the set from database populated with the sample data. The only thing that MySQL cannot do is to plot the result so I had to resort to perl for this (Update:Yes it can). It was at this point I realised something was not quite right when it came out looking more like a spreadeagled frog (see right) than the picture I expected.
The value of 4 as the bound comes from noting that the entire Mandelbrot set falls within a circle of radius 2 centred at the origin. These two queries, repeated multiple times, should be all that is required to generate the set from database populated with the sample data. The only thing that MySQL cannot do is to plot the result so I had to resort to perl for this (Update:Yes it can). It was at this point I realised something was not quite right when it came out looking more like a spreadeagled frog (see right) than the picture I expected.
It took me a while to realise that the problem was that I had been naive in the first UPDATE; when it set z_im=2*z_re*z_im+c_im it was using the value of z_re after it had already been updated. There are ways of getting round this with temporary tables but this is not really practical with a dataset of tens (or hundreds) of thousands of lines. The solution was to add extra columns for a temporary value of z and do the iteration in two steps, making the two queries:
UPDATE points SET
znew_re=POWER(z_re,2)-POWER(z_im,2)+c_re,
znew_im=2*z_re*z_im+c_im,
steps=steps+1
WHERE active=1;
UPDATE points SET
z_re=znew_re,
z_im=znew_im,
active=IF(POWER(z_re,2)+POWER(z_im,2)>4,0,1)
WHERE active=1;
And there you have it - the Mandelbrot set in two SQL queries.  Not only is this simpler than the usual algorithm that calculates each point in turn, it makes it very easy to produce animations like the one on the right. If anyone wants a copy to play around with the source code is here.
Not only is this simpler than the usual algorithm that calculates each point in turn, it makes it very easy to produce animations like the one on the right. If anyone wants a copy to play around with the source code is here.